Faculty & Research
Overview
Background/Introduction
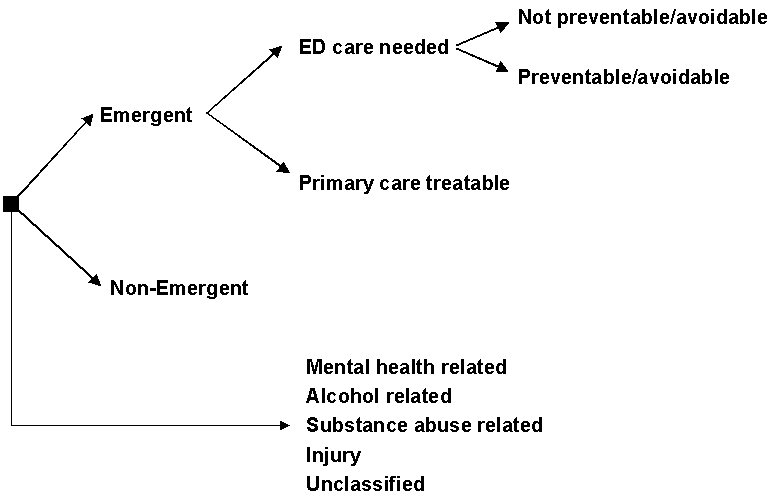
With support from the Commonwealth Fund, the Robert Wood Johnson Foundation, and the United Hospital Fund of New York, the NYU Center for Health and Public Service Research has developed an algorithm to help classify ED utilization. The algorithm was developed with the advice of a panel of ED and primary care physicians, and it is based on an examination of a sample of almost 6,000 full ED records. Data abstracted from these records included the initial complaint, presenting symptoms, vital signs, medical history, age, gender, diagnoses, procedures performed, and resources used in the ED. Based on this information, each case was classified into one of the following categories:
- Non-emergent - The patient's initial complaint, presenting symptoms, vital signs, medical history, and age indicated that immediate medical care was not required within 12 hours;
- Emergent/Primary Care Treatable - Based on information in the record, treatment was required within 12 hours, but care could have been provided effectively and safely in a primary care setting. The complaint did not require continuous observation, and no procedures were performed or resources used that are not available in a primary care setting (e.g., CAT scan or certain lab tests);
- Emergent - ED Care Needed - Preventable/Avoidable - Emergency department care was required based on the complaint or procedures performed/resources used, but the emergent nature of the condition was potentially preventable/avoidable if timely and effective ambulatory care had been received during the episode of illness (e.g., the flare-ups of asthma, diabetes, congestive heart failure, etc.); and
- Emergent - ED Care Needed - Not Preventable/Avoidable - Emergency department care was required and ambulatory care treatment could not have prevented the condition (e.g., trauma, appendicitis, myocardial infarction, etc.).
This information that was used to develop the algorithm required analysis of the full medical record. Since such detailed information is not generally available on computerized ED or claims records, these classifications were then "mapped" to the discharge diagnosis of each case in our sample to determine for each diagnosis the percentage of sample cases that fell into these four categories. For example, patients discharged with a final diagnosis of "abdominal pain" may include both patients who arrived at the ED complaining of stomach pain, as well as those who reported chest pain (an a possible heart attack). Accordingly, for abdominal pain, the algorithm assigns a specific percentage of the visit into the categories of "non-emergent", "emergent/primary care treatable", and "emergent/ED care needed-not preventable/avoidable" based on what we observed in our sample for cases with an ultimate discharge diagnosis of abdominal pain.
It is important to recognize that the algorithm is not intended as a triage tool or a mechanism to determine whether ED use in a specific case is "appropriate" (e.g., for reimbursement purposes). Since few diagnostic categories are clear-cut in all cases, the algorithm assigns cases probabilistically on a percentage basis, reflecting this potential uncertainty and variation.
Since the original development of the algorithm, users have expressed an interest in examining separately cases involving a primary diagnosis of injury, mental health problems, alcohol, or substance abuse. Accordingly, we have pulled these conditions out of the standard classification scheme, and tabulate them separately. There are also a residual of conditions (approximately 15%) where our sample was not of sufficient size to assign percentages for the standard classification - these conditions are also tabulated separately. See schematic diagram below of the algorithm.